Point-E and Shap-E
This example is a visual comparison of two popular text-to-3D methods that uses Rerun to compare the generation process and results.
Visual paper comparison visual-paper-comparison
OpenAI has released two models for text-to-3D generation: Point-E and Shape-E. Both of these methods are fast and interesting but still low fidelity for now.
First off, how do these two methods differ from each other? Point-E represents its 3D shapes via point clouds. It does so using a 3-step generation process: first, it generates a single synthetic view using a text-to-image diffusion model (in this case GLIDE).
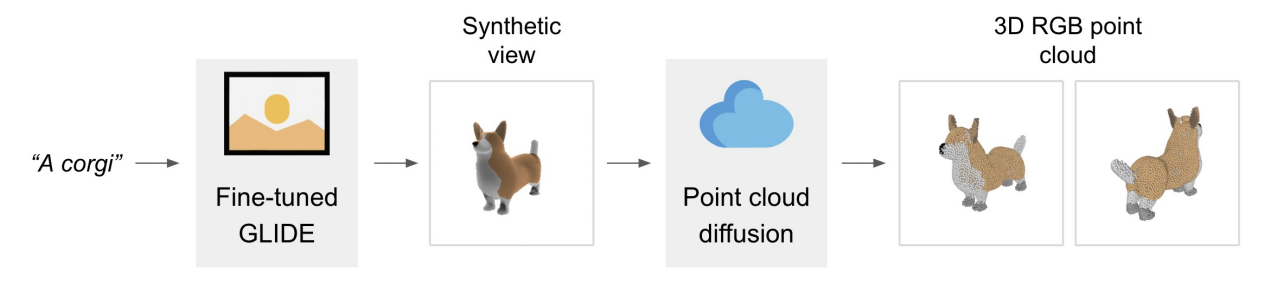
It then produces a coarse 3D point cloud using a second diffusion model which conditions on the generated image; third, it generates a fine 3D point cloud using an upsampling network. Finally, a another model is used to predict an SDF from the point cloud, and marching cubes turns it into a mesh. As you can tell, the results aren’t very high quality, but they are fast.
Shap-E improves on this by representing 3D shapes implicitly. This is done in two stages. First, an encoder is trained that takes images or a point cloud as input and outputs the weights of a NeRF.
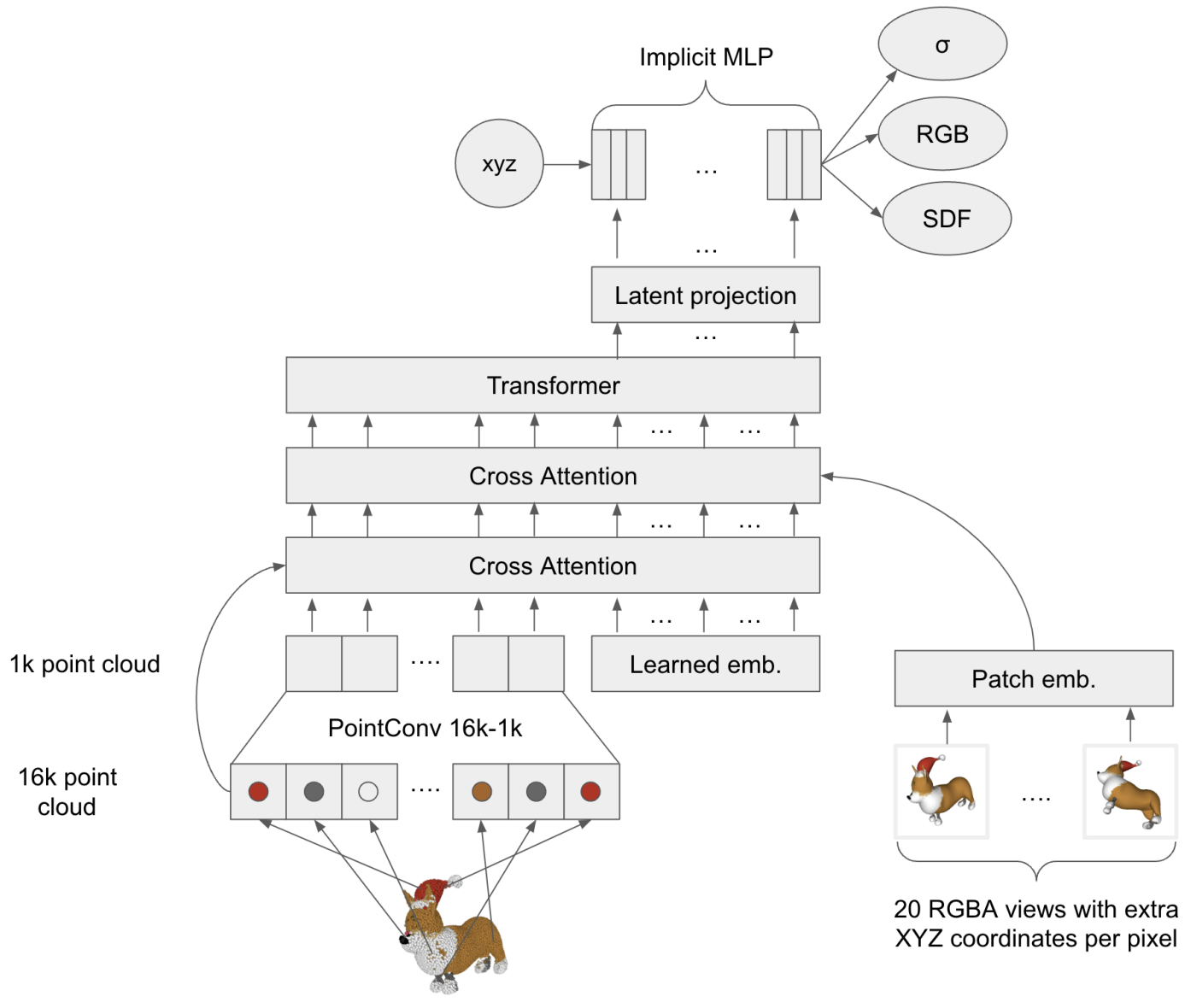
In the second stage, a diffusion model is trained on a dataset of NeRF weights generated by the previous encoder. This diffusion model is conditioned on either images or text descriptions. The resulting NeRF also outputs SDF values so that meshes can be extracted using marching cubes again. Here we see the prompt "a cheeseburger" turn into a 3D mesh a set of images.
When compared to Point-E on both image-to-mesh and text-to-mesh generation, Shap-E converges faster and reaches comparable or better sample quality despite modeling a higher-dimensional, multi-representation output space.
Check out the respective papers to learn more about the details of both methods: "Shap-E: Generating Conditional 3D Implicit Functions" by Heewoo Jun and Alex Nichol; "Point-E: A System for Generating 3D Point Clouds from Complex Prompts" by Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen.