LLM embedding-based named entity recognition
Visualize the BERT-based named entity recognition (NER) with UMAP Embeddings.
Used Rerun types used-rerun-types
TextDocument, AnnotationContext, Points3D
Background background
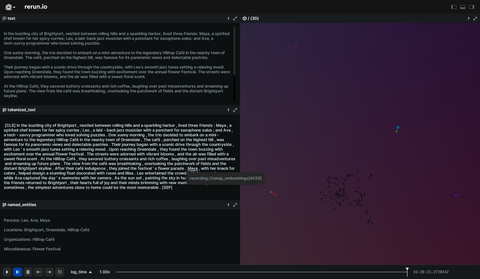
This example splits text into tokens, feeds the token sequence into a large language model (BERT), which outputs an embedding per token. The embeddings are then classified into four types of entities: location (LOC), organizations (ORG), person (PER) and Miscellaneous (MISC). The embeddings are projected to a 3D space using UMAP, and visualized together with all other data in Rerun.
Logging and visualizing with Rerun logging-and-visualizing-with-rerun
The visualizations in this example were created with the following Rerun code:
Text text
The logging begins with the original text. Following this, the tokenized version is logged for further analysis, and the named entities identified by the NER model are logged separately.
All texts are logged using TextDocument as a Markdown document to preserves structure and formatting.
Original text
rr.log("text", rr.TextDocument(text, media_type=rr.MediaType.MARKDOWN))Tokenized text
rr.log("tokenized_text", rr.TextDocument(markdown, media_type=rr.MediaType.MARKDOWN))Named entities
rr.log("named_entities", rr.TextDocument(named_entities_str, media_type=rr.MediaType.MARKDOWN))UMAP embeddings umap-embeddings
UMAP is used in this example for dimensionality reduction and visualization of the embeddings generated by a Named Entity Recognition (NER) model. UMAP preserves the essential structure and relationships between data points, and helps in identifying clusters or patterns within the named entities.
After transforming the embeddings to UMAP, the next step involves defining labels for classes using AnnotationContext.
These labels help in interpreting the visualized data.
Subsequently, the UMAP embeddings are logged as Points3D and visualized in a three-dimensional space.
The visualization can provide insights into how the NER model is performing and how different types of entities are distributed throughout the text.
# Define label for classes and set none class color to dark gray
annotation_context = [
rr.AnnotationInfo(id=0, color=(30, 30, 30)),
rr.AnnotationInfo(id=1, label="Location"),
rr.AnnotationInfo(id=2, label="Person"),
rr.AnnotationInfo(id=3, label="Organization"),
rr.AnnotationInfo(id=4, label="Miscellaneous"),
]
rr.log("/", rr.AnnotationContext(annotation_context))rr.log(
"umap_embeddings",
rr.Points3D(umap_embeddings, class_ids=class_ids),
rr.AnyValues(**{"Token": token_words, "Named Entity": entity_per_token(token_words, ner_results)}),
)Run the code run-the-code
To run this example, make sure you have the Rerun repository checked out and the latest SDK installed:
pip install --upgrade rerun-sdk # install the latest Rerun SDK
git clone git@github.com:rerun-io/rerun.git # Clone the repository
cd rerun
git checkout latest # Check out the commit matching the latest SDK releaseInstall the necessary libraries specified in the requirements file:
pip install -e examples/python/llm_embedding_nerTo experiment with the provided example, simply execute the main Python script:
python -m llm_embedding_ner # run the exampleYou can specify your own text using:
python -m llm_embedding_ner [--text TEXT]If you wish to customize it, explore additional features, or save it use the CLI with the --help option for guidance:
python -m llm_embedding_ner --help